Parallelisierte Berechnung von Hitzeausbreitung
Visualisierung
Die Berechneten Werte werden abschließend mit einem Skript und Falschfarben-Darstellung visualisiert:

Problembeschreibung
Es soll die Ausbreitung von Hitzewerten auf einem Feld berechnet werden. Die Berechnung der Werte an jedem Punkt der Matrix basiert auf den Werten der umliegenden Punkte zum vorherigen Zeitpunkt sowie dem eigenen Wert. Die Werte werden zu jedem Zeitpunkt neu berechnet und die Hitze soll sich von oben nach unten ausbreiten.
Voraussetzungen für die Berechnung sind:
* Matrix
* Initialwerte der ersten Zeile der Matrix
* Anzahl der Zeitschritte
Jeder Wert wird berechnet nach der Formel:
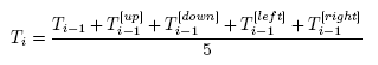
Veranschaulichung
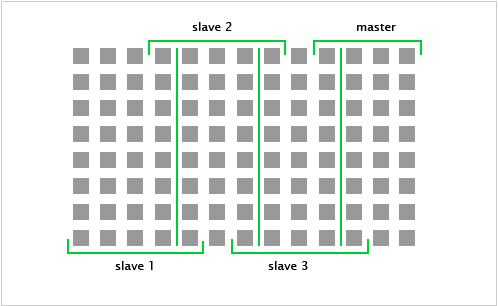
Die Matrix wird in gleich große Abschnitte unterteilt und an die Arbeitsstationen verteilt.
Der Master erhält den letzten Part, der ggf. kleiner sein kann als die anderen Abschnitte.
Jede Arbeitsstation bekommt folgende Informationen:
* Länge des zu berechnenden Feldes in x- und in y-Richtung
* Vorgänger- und Nachfolger-System
* Anzahl der Zeitschritte
* Gesamtgröße der Matrix
Dann werden die Werte der Matrix gesendet. Die Slaves bekommen hierbei neben den Daten für ihren Zuständigkeitsbereich zusätzlich die Werte aus den angrenzenden Spalten:
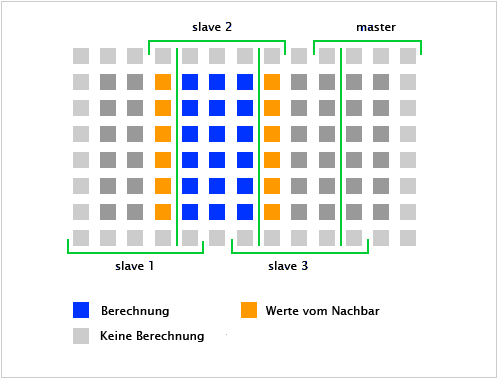
Die angrenzenden Spalten werden zwischen den Systemen ausgetauscht. Die Ränder der Matrix werden nicht neu kalkuliert. Sie werden lediglich zur Berechnung der Werte herangezogen, so dass wie in Abb. 2 zu sehen ist, nur die dunkelgrauen und blauen Punkte neu berechnet werden.
Programmbeschreibung
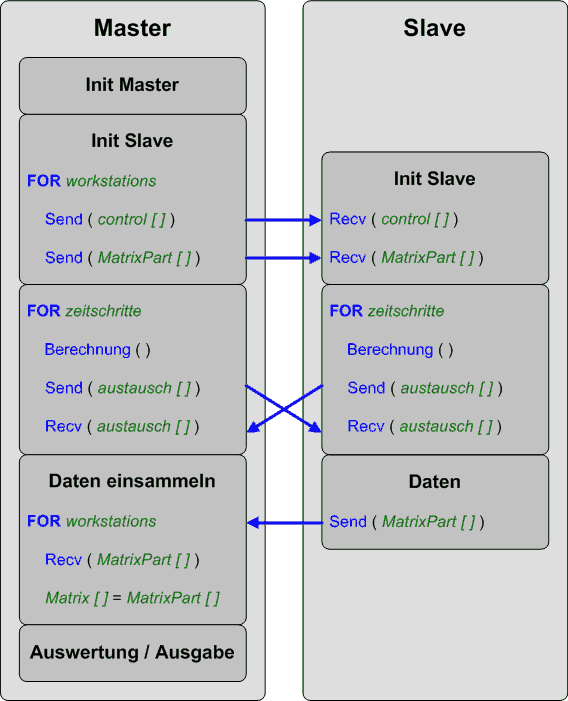
Der Master berechnet die Arbeitspakete anhand der Matrixgröße und der Anzahl der Workstations, sich selbst mit eingeschlossen. Er sendet mit MPI_send() folgende Daten an alle Workstations:
Anfangsadresse des Sendepuffers, Anzahl der Elemente des Sendepuffers, Typ der Elemente des Sendepuffers und den Rang des Empfängerprozesses.
Die ersten Slaves bekommen evtl. mehr Aufgaben, weil sie als erstes mit den Berechnungen beginnen können. Alle Workstations führen je Zeitschritt die Berechnungen durch und senden anschließend die Ergebnisse am Rand ihres zu berechnenden Blocks an das Vorgänger- und Nachfolgersystem.
Die Daten werden mit dem blockierenden MPI_send() und MPI_recv() ausgetauscht. Hierbei wird die Anfangsadresse des Sendepuffers gesendet. An dieser Speicheradresse liegt jeweils ein Array mit der Länge der Zeilenanzahl der Matrix (entspricht einer Spalte).
Da das Message Passing Interface Problemlösungen mit verteiltem Hauptspeicher (Distributed Memory) realisiert, wird für den Wertaustausch auf den lokalen Speicher der Workstations zugegriffen. Das wird später in den Auswertungen sichtbar.
Nach dem Durchlauf aller Berechnungsschritte (Zeitschritte), sammelt der Master mittels MPI_recv() die Ergebnisse von jedem Slave ein und gibt das Ergebnis in einer Datei aus.
Performance Analyse
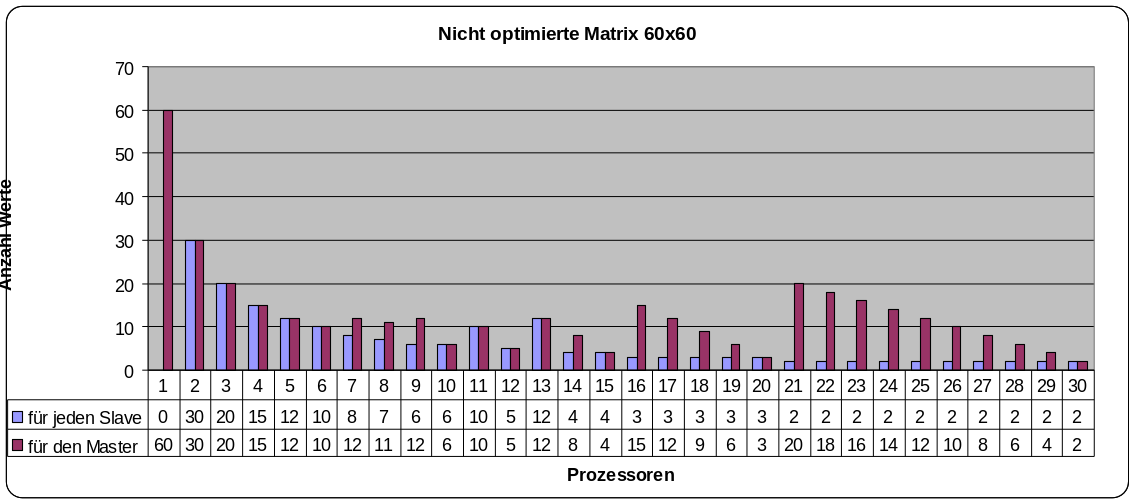
In einer ersten Programmversion wurden die Aufgabenpakete nicht gleichmäßig verteilt, was erhebliche Ineffizienz verursachte.
Diese Belegarbeit wurde im Fach Parallele Programmierung im 2er Team erstellt.